Enhance Data Integrity
Duplicate Identification Services
Eliminate duplicate records to effectively connect with your customers.
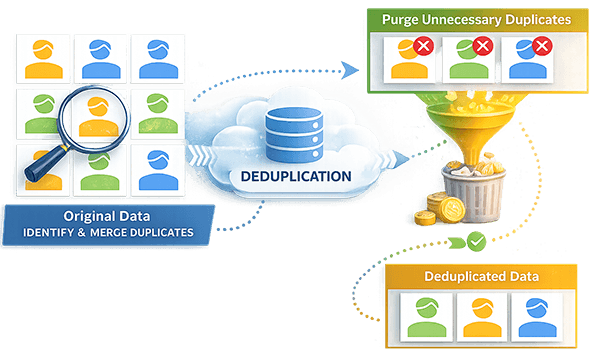



Benefits
The Impact of Duplicate-Free Data

Improved Data Quality
Identifying and removing duplicate records ensures that your data is accurate, consistent, and reliable. This leads to better data integrity and trustworthiness.

Cost Savings
Eliminating duplicates decreases the amount of unnecessary data processing. It also minimizes the risk of redundant communications.

Streamlined Data Integration
Clean data simplifies the process of integrating data from multiple sources, making it easier to create a unified view of the information and derive meaningful insights.

Regulatory Compliance
Maintaining accurate and consistent data helps your organization comply with data protection regulations and industry standards, reducing the risk of penalties and legal issues.

Ready to optimize your data?
Connect with us today to discover how our Duplication Identification Services can streamline your data processes, ensuring accuracy and efficiency

Get the White Paper: Identify Top Prospects With Lead Scoring
The Impact of Our Expertise
Trusted by Leading B2B, Healthcare, Technology, and Media Brands
Hear from clients who rely on Reach Marketing for marketing technology, database, and lead generation support.


”The Reach Marketing staff you have assigned to Northwell are some of the most dedicated, gifted and intelligent people I have ever had the pleasure to work with. Our Marketing Automation and Database teams have united in a very powerful way which has allowed us to achieve exceptional performance, witnessed by the results we have achieved.”
VP Customer Insights & Analytics, Northwell Health
“Reach Marketing has been an invaluable database and audience development partner. They have facilitated significant growth within our database and provided indispensable strategic support throughout the entire process. ”
Vice President Regional Marketing / Database Marketing, Gartner
Recent Posts

B2B Email Marketing for Lead Generation Without List Burnout
What Prevents B2B Email Marketing From Damaging List Quality B2B email marketing avoids list burnout when relevance, timing, and audience fit are consistently aligned. List degradation occurs when contacts receive…

What is Database Marketing?: A Complete Analysis
Database marketing has emerged as a pivotal strategy in the contemporary business landscape, enabling organizations to harness customer data for targeted marketing efforts. This article delves into the intricacies of…
Data Modeling: The Blueprint for Effective Marketing Strategies
In today’s data-driven world, businesses are inundated with vast amounts of information from various sources. To harness this data effectively, it’s crucial to have a structured approach to organizing and…
Need More Information?
Frequently Asked Questions
Explore frequently asked questions about our services, processes, and industry insights.
Duplicate identification offers several key benefits:
- Enhanced Data Quality: It helps ensure that the data is accurate and free from redundancies, which improves the reliability of data-driven decisions.
- Increased Efficiency: By removing duplicates, data processing speeds improve, leading to faster insights and more efficient operations.
- Cost Reduction: It helps reduce costs associated with data storage and processing by eliminating unnecessary data duplication.
Duplicate identification plays a crucial role in analytics by:
- Improving Accuracy: Ensuring data is unique and consistent leads to more accurate analysis and reporting.
- Enhancing Insights: Clean data allows for more precise and deep insights because the underlying data reflects a true picture of the situation without skewed results due to duplicates.
- Supporting Compliance: For industries where data accuracy is critical for compliance and reporting, having duplicate-free data is essential.
Reach Marketing has been serving clients since its establishment in 2011. Over the years, our experience has deepened, allowing us to refine our strategies and services to better meet the evolving needs of our clients. Our long-standing presence in the industry is a testament to our commitment to excellence and the trust our clients place in us.
- Pattern Matching: Identifying duplicates based on specific patterns or criteria in the data.
- Data Fingerprinting: Creating unique identifiers for records to easily spot duplicates.
- Machine Learning Algorithms: Using advanced algorithms to learn from the data and automatically identify potential duplicates with high accuracy.
- Rule-based Systems: Setting specific rules that define what constitutes a duplicate, based on the unique needs of the organization.
Data hygiene refers to the processes and practices that ensure the accuracy, consistency, and reliability of data within a system. It involves regular data cleaning and maintenance to prevent errors, duplication, and corruption, thereby enhancing the overall quality of data. Effective data hygiene practices are essential for making informed business decisions, improving operational efficiency, and maintaining compliance with regulatory standards.
Key components of data hygiene include data cleaning, which removes or corrects inaccuracies, inconsistencies, and errors; data deduplication, which eliminates duplicate records to ensure each piece of data is unique; and data standardization, which ensures data follows a consistent format and structure across all datasets.
Additionally, data validation checks data for accuracy and completeness against predefined rules, while data enrichment adds missing or supplemental information from external sources to enhance the existing data. Data profiling analyzes data to understand its structure, content, and quality, identifying potential issues. Continuous data monitoring tracks data quality to detect and address issues promptly, and data transformation converts data from one format or structure to another to ensure consistency and usability. Address verification confirms and corrects postal addresses to improve mail delivery and communication accuracy, while contact validation verifies the accuracy of contact information such as email addresses and phone numbers.
Maintaining good data hygiene is crucial for businesses to ensure their data is trustworthy and actionable, leading to more effective decision-making and better business outcomes.